Home
👥 AgentIF Team •
📚 AgentIF Paper •
![]() Code •
📊 AgentIF Dataset
Code •
📊 AgentIF Dataset
![]()
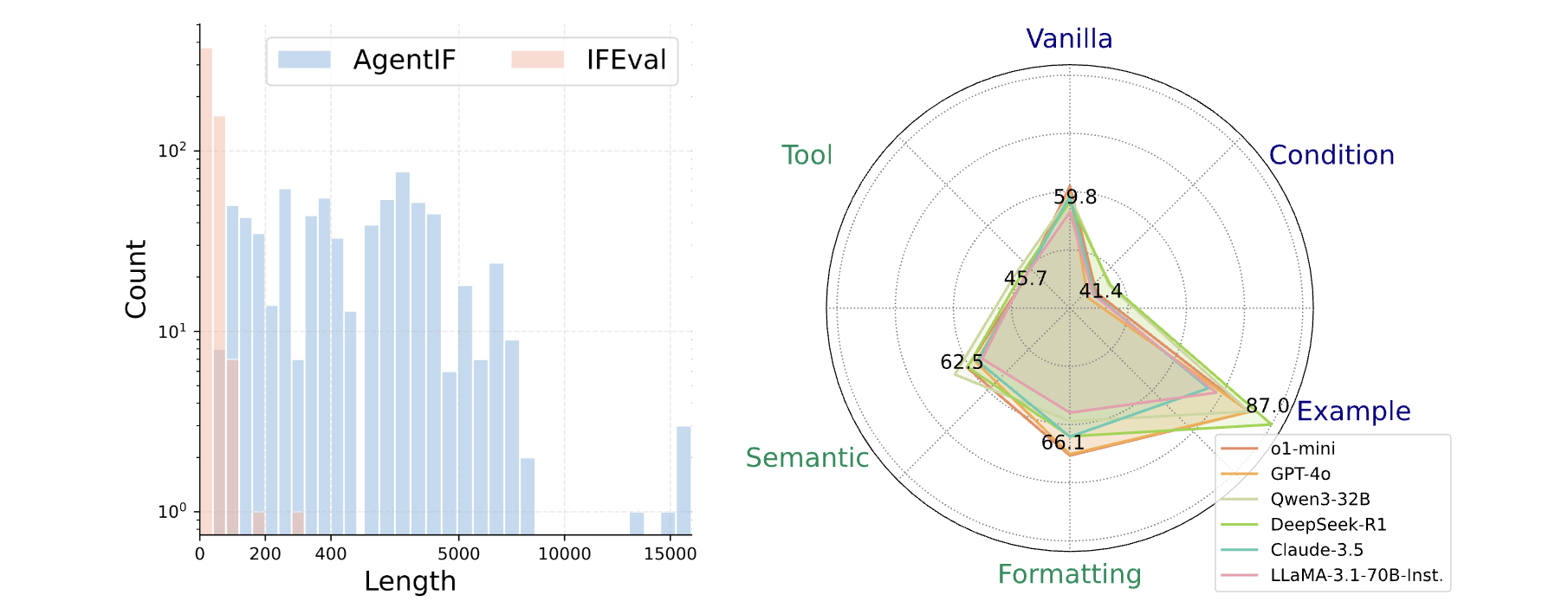
We introduce AgentIF, the first benchmark for systematically evaluating LLM instruction following ability in agentic scenarios. AgentIF features three key characteristics: (1) Realistic, constructed from 50 real-world agentic applications. (2) Long, averaging 1,723 words with a maximum of 15,630 words. (3) Complex, averaging 11.9 constraints per instruction, covering diverse constraint types, such as tool specifications and condition constraints. Here is the instruction length distribution in AgentIF, along with the success rates of several representative LLMs across the constraint dimensions we propose:
 An example instruction of AgentIF:
An example instruction of AgentIF:

Leaderboard
Metrics
- Constraint Success Rate (CSR) measures the proportion of individual constraints that are correctly satisfied by the model’s response.
- Instruction Success Rate (ISR) measures the proportion of instructions for which all constraints are satisfied.
Performance Across Constraint Categories
- Press each model to get its latest results. Or press this key to reach the depository of all results: Results
| Models | Dimension | Type | ISR | CSR | ||||
| Vanilla | Condition | Example | Formatting | Semantic | Tool | |||
| [T] o1-mini | 59.8 | 37.5 | 80.8 | 66.1 | 59.1 | 43.2 | 26.9 | 59.8 |
| [N] GPT-4o | 58.0 | 35.1 | 80.8 | 65.8 | 56.5 | 43.2 | 26.4 | 58.5 |
| [N] Qwen3-32B | 57.5 | 41.1 | 80.6 | 57.7 | 62.5 | 45.7 | 24.9 | 58.4 |
| [T] QwQ-32B | 57.5 | 35.6 | 82.7 | 61.4 | 59.4 | 43.2 | 27.2 | 58.1 |
| [T] DeepSeek-R1 | 56.1 | 41.4 | 87.0 | 61.4 | 58.9 | 44.4 | 22.2 | 57.9 |
| [T] GLM-Z1-32B | 56.7 | 37.9 | 83.6 | 60.2 | 59.6 | 43.1 | 23.8 | 57.8 |
| [N] DeepSeek-V3 | 54.9 | 41.5 | 84.5 | 59.3 | 58.9 | 40.8 | 21.9 | 56.7 |
| [N] Claude-3-5-Sonnet | 57.3 | 36.9 | 69.2 | 61.5 | 56.0 | 43.3 | 24.9 | 56.6 |
| [N] Meta-Llama-3.1-70B-Instruct | 55.1 | 35.0 | 84.3 | 61.6 | 55.6 | 42.8 | 20.9 | 56.3 |
| [T] DeepSeek-R1-Distill-Qwen-32B | 54.5 | 39.6 | 73.1 | 55.7 | 57.2 | 45.2 | 20.7 | 55.1 |
| [T] DeepSeek-R1-Distill-Llama-70B | 55.4 | 37.7 | 69.2 | 56.5 | 56.6 | 44.1 | 19.9 | 55.0 |
| [N] Meta-Llama-3.1-8B-Instruct | 53.5 | 36.6 | 71.4 | 55.6 | 54.8 | 43.5 | 19.9 | 53.6 |
| [S] Crab-DPO-7B | 48.3 | 24.3 | 57.5 | 48.8 | 47.4 | 41.9 | 10.1 | 47.2 |
| [N] Mistral-7B-Instruct-v0.3 | 47.9 | 29.2 | 53.8 | 47.0 | 48.6 | 39.8 | 11.5 | 46.8 |
| [S] Conifer-DPO-7B | 45.6 | 27.0 | 50.5 | 42.0 | 46.9 | 41.8 | 10.7 | 44.3 |
| Success rates (%) of various proprietary and open-source LLMs on AgentIF, sorted by CSR in descending order. [N] denotes non-thinking models, [T] denotes thinking models, and [S] denotes models explicitly designed for instruction following by the academic community. | ||||||||
Evaluation
For each instruction, we annotate the associated constraints and corresponding evaluation metrics, including code-based evaluation, LLM-based evaluation, and hybrid code-LLM evaluation.
How to evaluation
- Clone the remote repository to your local environment. The necessary data is already included, so no further actions are needed.
git clone https://github.com/THU-KEG/AgentIF.git - (Optional) To evaluate a model hosted locally, deploy it using vLLM. Use a command similar to the following:
CUDA_VISIBLE_DEVICES=<CUDA_ID> vllm serve "<your_model_path>" \ --served-model-name <your_model_name> \ --port 8008 \ --tensor-parallel-size <num_gpus> \ --max-model-len 32000 \ --gpu-memory-utilization 0.9 -
Specify the target model and the evaluator in the
run.shfile. To reproduce our results, we recommend usinggpt-4o-2024-11-20.Model_Name="" # Name of the model to evaluate Model_Name_URL="" # Endpoint of the model (e.g., OpenAI API URL or local vLLM URL) Model_Name_API_Key="EMPTY" # Set to "EMPTY" for local vLLM; otherwise, provide your API key Evaluator_Model_Backbone="" # Name of the evaluator model; use `gpt-4o-2024-11-20` for reproducibility Evaluator_URL="" # Base URL of the evaluator; use `https://api.openai.com/v1` to match our setup Evaluator_API_Key="" # API key for the evaluator -
Then run the script to start the evaluation.
sh run.sh
Data Format
Each data instance in AgentIF is structured as follows:
{
"input": [
{ "role": "system", "content": "..." },
{ "role": "user", "content": "..." }
],
"constraints": [
{
"id": 0,
"desc": "...", // Constraint description
"other_info": { // Auxiliary information for evaluation
"...": "..."
},
"dimension": "...", // Constraint Presentation Type
"type": "...", // Constraint Type
"is_meta": false, // Whether it is a meta-constraint
"evaluation": [ // Evaluation Method
{
"type": "llm", // LLM-based evaluation
"required_keys": ["response"],
"exec": "..." // Evaluation prompt for LLM
},
{
"type": "code", // Code-based evaluation
"exec": "..." // Executable code snippet
}
]
}
]
}
Citation
@misc{qi2025agentifbenchmarkinginstructionfollowing,
title={AGENTIF: Benchmarking Instruction Following of Large Language Models in Agentic Scenarios},
author={Yunjia Qi and Hao Peng and Xiaozhi Wang and Amy Xin and Youfeng Liu and Bin Xu and Lei Hou and Juanzi Li},
year={2025},
eprint={2505.16944},
archivePrefix={arXiv},
primaryClass={cs.AI},
url={https://arxiv.org/abs/2505.16944},
}